
The Truth about Sessions
Published in PHP Magazine on 15 Dec 2003Nearly every PHP application uses sessions. This article takes a detailed look at implementing a secure session management mechanism with PHP. Following a fundamental introduction to HTTP, the challenge of maintaining state, and the basic operation of cookies, I will step through simple and effective methods that can be used to increase the security and reliability of your stateful PHP applications.
It is a common misconception that PHP provides a certain level of security with its native session management features. On the contrary, PHP simply provides a convenient mechanism. It is up to the developer to provide the complete solution, and as you will see, there is no one solution that is best for everyone.
Statelessness
HTTP is a stateless protocol. This is because there is nothing within the protocol that requires the browser to identify itself during each request, and there is also no established connection between the browser and the web server that persists from one page to the next. When a user visits a web site, the user's browser sends an HTTP request to the web server, which in turn sends an HTTP response in reply. This is the extent of the communication, and it represents a complete HTTP transaction.
Because the web relies on HTTP for communication, maintaining state in a web application can be particularly challenging for developers. Cookies are an extension of HTTP that were introduced to help provide stateful HTTP transactions, but privacy concerns have prompted many users to disable support for cookies. State information can be passed in the URL, but accidental disclosure of this information poses serious security risks. In fact, the very nature of maintaining state requires that the client identify itself, yet the security-conscious among us know that we should never trust information sent by the client.
Despite all of this, there are elegant solutions to the problem of maintaining state. There is no perfect solution, of course, nor is there one solution that can satisfy everyone's needs. This article introduces some techniques that can reliably provide statefulness as well as defend against session-based attacks such as session hijacking. Along the way, you will learn how cookies really work, what PHP sessions do, and what is required to hijack a session.
HTTP Overview
In order to appreciate the challenge of maintaining state as well as choose the best solution for your needs, it is important to understand a little bit about the underlying architecture of the web, the Hypertext Transfer Protocol (HTTP).
A visit to http://example.org/ requires the web browser to send an HTTP request to example.org on port 80. The syntax of the request is something like the following:
GET / HTTP/1.1Host: example.org
The first line is called the request line, and the second parameter (a slash in this example) is the path to the resource being requested. The slash represents the document root; the web server translates the document root to a specific path in the filesystem. Apache users might be familiar with setting this path with the DocumentRoot directive. If http://example.org/path/to/script.php is requested, the path to the resource given in the request is /path/to/script.php. If the document root is defined to be /usr/local/apache/htdocs, the complete path to the resource that the web server uses is /usr/local/apache/htdocs/path/to/script.php.
There are many technologies such as mod_rewrite that offer more flexibility when mapping a URL to a particular resource.
The second line illustrates the syntax of an HTTP header. The header in this example is Host, and it identifies the domain name of the host from which the browser intends to be requesting a resource. This header is required by HTTP/1.1 and helps to provide a mechanism to support virtual hosting, multiple domains being served by a single public IP address. There are many other optional headers that can be included in the request, and you may be familiar with referencing these in your PHP code; examples include $_SERVER['HTTP_REFERER'] to refer to the Referer header and $_SERVER['HTTP_USER_AGENT'] to refer to the User-Agent header.
Of particular note in this example request is that there is nothing within it that can be used to uniquely identify the client. Some developers resort to information gathered from TCP/IP (such as the IP address) for unique identification, but this approach has many problems. Most notably, a single user can potentially use a different IP address for each request (as is the case with large ISPs such as AOL), and multiple users can potentially use the same IP address (as is the case in many computer labs using an HTTP proxy). These situations can cause a single user to appear to be many, or many users to appear to be one. For any reliable and secure method of providing state, only information obtained from HTTP can be used.
The first step in maintaining state is to somehow uniquely identify each client. Because the only reliable information that can be used for such identification must come from the HTTP request, there needs to be something within the request that can be used for unique identification. There are a few ways to do this, but the solution designed to solve this particular problem is the cookie.
Cookies
The realization that there must be a method of uniquely identifying clients has resulted in cookies, a fairly creative solution. Cookies are easiest to understand if you consider them to be an extension of the HTTP protocol, which is precisely what they are. Cookies are defined by RFC 2965, although the original specification written by Netscape more closely resembles industry support.
There are two HTTP headers that are necessary to implement cookies, Set-Cookie and Cookie. A web server includes a Set-Cookie header in a response to request that the browser include this cookie in future requests. A compliant browser that has cookies enabled includes the Cookie header in all subsequent requests (that satisfy the conditions defined in the Set-Cookie header) until the cookie is expired. A typical scenario consists of two transactions (four HTTP messages):
- Client sends an HTTP request.
- Server sends an HTTP response that includes the
Set-Cookieheader. - Client sends an HTTP request that includes the
Cookieheader. - Server sends an HTTP response.
This exchange is illustrated in Figure 1.
Figure 1:
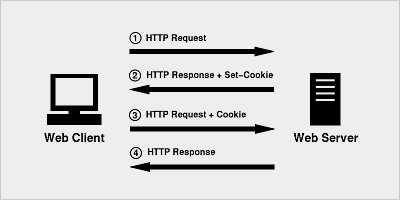
The addition of the Cookie header in the client's second request provides information that the server can use to uniquely identify the client. It is also at this point that the server (or a server-side PHP script) can determine whether the user has cookies enabled. Although the user can choose to disable cookies, it is fairly safe to assume that the user's preference will not change while interacting with your application. This fact can prove to be very useful, as will soon be demonstrated.
GET and POST Data
There are two additional methods that a client can use to send data to a server, and these methods predate cookies. A client can include information in the URL being requested, whether in the query string or as part of the path. As an example of utilizing the query string, consider the following example request:
GET /index.php?foo=bar HTTP/1.1Host: example.org
The receiving script, index.php, can reference $_GET['foo'] to reference the value bar. Because of this, most PHP developers refer to this data as GET data (others sometimes refer to it as query string data or URL variables). One common point of confusion is that GET data can exist in a POST request, because it is simply part of the URL being requested and doesn't rely on the request method.
Another method that a client can use to send information is by utilizing the content portion of an HTTP request. This technique requires that the request method be POST, and an example of such a request is as follows:
POST /index.php HTTP/1.1Host: example.orgContent-Type: application/x-www-form-urlencodedContent-Length: 7foo=bar
In this case, the receiving script, index.php, can reference $_POST['foo'] to reference the value bar. PHP developers typically refer to this data as POST data, and this is how a browser passes data submitted from a form where the method is POST.
A request can potentially have both types of data, like this:
POST /index.php?myget=foo HTTP/1.1Host: example.orgContent-Type: application/x-www-form-urlencodedContent-Length: 11mypost=bar
These two additional methods of sending data in a request can provide substitutes for cookies. Unlike cookies, GET and POST data support is not optional, so these methods can also be more reliable. Consider a unique identifier called PHPSESSID included in the request URL as follows:
GET /index.php?PHPSESSID=12345 HTTP/1.1Host: example.org
This achieves the same goal as the Cookie header, because the client identifies itself, but it is much less automatic for the developer. Once a cookie is set, it is the browser's responsibility to return it in subsequent requests. To propagate the unique identifier through the URL, the developer must ensure that all links, form submission buttons, and the like contain the appropriate query string (PHP can help with this if you enable session.use_trans_sid). In addition, GET data is displayed in the URL and is much more exposed than a cookie. In fact, unsuspecting users might bookmark such a URL, send it to a friend, or do any number of things that can accidentally reveal the unique identifier.
Although POST data is less likely to be exposed, propagating the unique identifier as a POST variable requires all requests to be POST requests. This is not a convenient option, although your application design might make it more viable.
Session Management
Until now, I have been discussing state. This is a rather low-level detail that involves associating one HTTP transaction with another. The more useful feature that you are likely to be familiar with is session management. Session management not only relies on the ability to maintain state, but it also requires that you maintain data uniquely associated with each user. This data is often called session data, because it is associated with a specific user's session. If you use PHP's built-in session management mechanism, session data is persisted for you (in /tmp by default) and available in the $_SESSION superglobal. A simple example of using sessions involves the persistence of session data from one page to the next. Listing 1, start.php, demonstrates how this can be done.
Listing 1:
<?phpsession_start();$_SESSION['foo'] = 'bar';?><a href="continue.php">continue.php</a>
Assuming the user clicks the link in start.php, the receiving script (continue.php) will be able to access the same session variable, $_SESSION['foo']. This is shown in Listing 2.
Listing 2:
<?phpsession_start();echo $_SESSION['foo']; /* bar */?>
Serious security risks exist when you write code like this without understanding what PHP is doing for you. Without this knowledge, you will find it difficult to debug session errors or provide any reasonable level of security.
Impersonation
It is a common misconception that PHP's native session management mechanism provides safeguards against common session-based attacks. On the contrary, PHP simply provides a convenient mechanism. It is the developer's responsibility to provide the appropriate safeguards for security. As mentioned previously, there is no perfect solution, nor a best solution that is right for everyone.
To explain the risk of impersonation, consider the following series of events:
- Good Guy visits
http://example.org/and logs in. example.orgsets a cookie,PHPSESSID=12345.- Bad Guy visits
http://example.org/and presents a cookie,PHPSESSID=12345. example.orgmistakes Bad Guy for Good Guy.
These events are illustrated in Figure 2.
Figure 2:
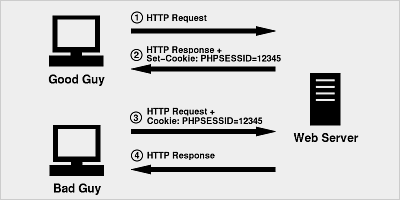
Of course, this scenario assumes that Bad Guy somehow discovers or guesses the valid PHPSESSID that belongs to Good Guy. While this may seem unlikely, it is an example of security through obscurity and is not something that should be relied upon. Obscurity isn't a bad thing, of course, and it can help, but there needs to be something more substantial in place that offers reliable protection against such an attack.
Preventing Impersonation
There are many techniques that can be used to complicate impersonation or other session-based attacks. The general approach is to make things as convenient as possible for your legitimate users and as complicated as possible for the attackers. This can be a very challenging balance to achieve, and the perfect balance largely depends on the application design. So, you are ultimately the best judge.
The simplest valid HTTP/1.1 request consists of a request line and the Host header:
GET / HTTP/1.1Host: example.org
If the client is passing the session identifier as PHPSESSID, this can be passed in a Cookie header as follows:
GET / HTTP/1.1Host: example.orgCookie: PHPSESSID=12345
Alternatively, the client can pass the session identifier in the request URL:
GET /?PHPSESSID=12345 HTTP/1.1Host: example.org
The session identifier can also be included as POST data, but this typically involves a less friendly user experience and is the least popular approach.
Because information gathered from TCP/IP cannot be reliably used to help strengthen the security of the mechanism, it seems that there is little that a web developer can do to complicate impersonation. After all, an attacker must only provide the same unique identifier that a legitimate user would in order to impersonate that user and hijack the session. Thus, it would appear that the only protection is to either keep the session identifier hidden or to make it difficult to guess (preferably both).
PHP generates a random session identifier that is practically impossible to guess, so this concern is already mitigated. Preventing the attacker from discovering a valid session identifier is much more difficult, because much of this responsibility lies outside of the developer's realm of control.
There are many situations that can result in the exposure of a user's session identifier. GET data can be mistakenly cached, observed by an onlooker, bookmarked, or emailed. Cookies provide a safer mechanism, but users can disable support for cookies, ruling out the possibility of using them, and past vulnerabilities in Internet Explorer have been known to reveal cookies to unauthorized sites.
Thus, a developer can be fairly certain that a session identifier cannot be guessed, but the possibility that it can be revealed to an attacker is more likely, regardless of the method used to propagate it. Something additional is needed to help prevent impersonation.
In practice, a typical HTTP request includes many optional headers in addition to Host. For example, consider the following request:
GET / HTTP/1.1Host: example.orgCookie: PHPSESSID=12345User-Agent: Mozilla/5.0 (Macintosh; U; Intel Mac OS X; en-US; rv:1.8.1.1) Gecko/20061204 Firefox/2.0.0.1Accept: text/html;q=0.9, */*;q=0.1Accept-Charset: ISO-8859-1, utf-8;q=0.66, *;q=0.66Accept-Language: en
This example includes four optional headers, User-Agent, Accept, Accept-Charset, and Accept-Language. Because these headers are optional, it is not very wise to rely on their presence. However, if a user's browser does send these headers, is it safe to assume that they will be present in subsequent requests from the same browser? The answer is yes, with very few exceptions. Assuming that the previous example is a request sent from a current user with an active session, consider the following request sent shortly thereafter:
GET / HTTP/1.1Host: example.orgCookie: PHPSESSID=12345User-Agent: Mozilla/5.0 (compatible; IE 6.0 Microsoft Windows XP)
Because the same unique identifier is being presented, the same PHP session will be accessed. If the browser is identifying itself differently than noted in previous interactions, should it be assumed that this is the same user?
It is hopefully clear that this is not desirable, yet this is exactly what happens if you do not write code that specifically checks for such situations. Even in cases where you cannot be sure that the request is an impersonation attack, simply prompting the user for a password can help prevent impersonation without adversely affecting your users too much. This is an important point.
You can add User-Agent checking to your security model with code similar to that Listing 3.
Listing 3:
<?phpsession_start();if (md5($_SERVER['HTTP_USER_AGENT']) != $_SESSION['HTTP_USER_AGENT']) {/* Prompt for Password */exit;}/* Rest of Code */?>
Of course, you will need to first store the MD5 digest of the user agent whenever you first begin a session, as shown in Listing 4.
Listing 4:
<?phpsession_start();$_SESSION['HTTP_USER_AGENT'] = md5($_SERVER['HTTP_USER_AGENT']);?>
While it is not necessary that you use the MD5 of User-Agent, it helps provide consistency and eliminates the necessity to filter $_SERVER['HTTP_USER_AGENT'] before using it. Because this data originates from a remote source, it should not be blindly trusted, but the format of an MD5 digest is consistent.
Now that you enforce User-Agent consistency, an attacker must complete two steps in order to hijack a session:
- Capture a valid session identifier.
- Present the victim's
User-Agentheader in the impersonation attempt.
While this is clearly possible, it is more slightly more complicated, therefore the session mechanism is already more secure.
Other headers can be added in this way, and you can even use a combination of headers as a fingerprint. If you also include some secret padding of some sort, this fingerprint becomes practically impossible to guess. Consider the example Listing 5.
Listing 5:
<?phpsession_start();$fingerprint = 'SHIFLETT' . $_SERVER['HTTP_USER_AGENT'];$_SESSION['fingerprint'] = md5($fingerprint . session_id());?>
The Accept header should not be used in the fingerprint, because some browsers vary the value of this header when the user refreshes the page.
With a fingerprint that is difficult to guess, little is gained without using it. Consider a session mechanism where the fingerprint is propagated just like the session identifier. In this case, an attacker must complete the following three steps to successfully hijack the session:
- Capture a valid session identifier.
- Present the same HTTP headers used to generate the fingerprint.
- Present the victim's fingerprint.
If both the session identifier and the fingerprint are propagated as GET data, it is possible that an attacker who can obtain one will also have access to the other. A safer approach is to utilize two different methods of propagation, GET data and cookies. Of course, this relies upon the user's preferences, but an extra level of protection can be offered to those who enable cookies. Thus, if an attacker obtains the unique identifier by way of a browser vulnerability, the fingerprint is still likely to be unknown.
There are many more techniques that can be used to help strengthen the security of your session mechanism. Hopefully you are well on your way to creating some techniques of your own. After all, you are the expert of your own applications, so armed with a good understanding of sessions, you are the best person to implement some additional security.
Obscurity
I would like to dispel a common myth about obscurity. The myth is that there is "no security through obscurity." As I mentioned earlier, obscurity is not something that offers adequate protection, nor should it be relied upon. However, this does not mean that there is absolutely nothing to be gained. Backed by a secure session mechanism, obscurity can offer a bit of additional security.
Simply using misleading variable names for the session identifier and fingerprint can help. You can also propagate decoy data to mislead a potential attacker. These techniques certainly should never be relied upon for protection, of course, but you will not waste your time by implementing a bit of obscurity in your own mechanism.
Summary
I hope that you have gained several things from this article. Notably, you should now have a basic understanding of how the web works, how statefulness is achieved, what a cookie really is, how PHP sessions work, and some techniques that you can use to improve the security of your sessions.
If you enjoyed this article, you might also be interested in these others:
- Security Corner: Session Fixation
- Security Corner: Session Hijacking
- Guru Speak: Storing Sessions in a Database
If you develop a secure session mechanism of your own, please feel free to share it with the community. I would love to hear about your own solutions, and I hope this article provides the background information necessary to support your own creativity.
